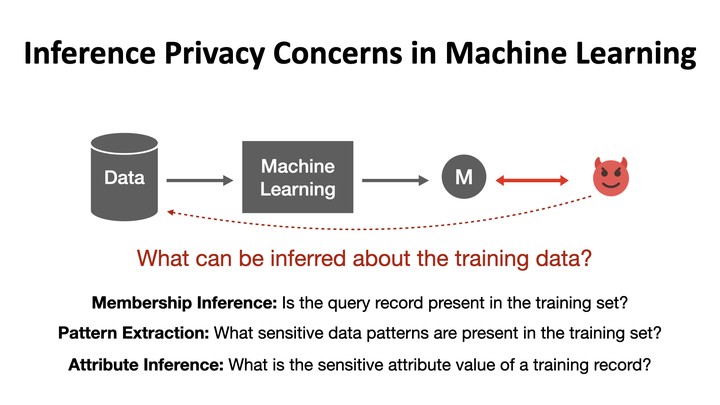
Machine learning models have been shown to leak sensitive information about their training data. An adversary having access to the model can infer different types of sensitive information, such as learning if a particular individual’s data is in the training set, extracting sensitive patterns like passwords in the training set, or predicting missing sensitive attribute values for partially known training records. This dissertation quantifies this privacy leakage. We explore inference attacks against machine learning models including membership inference, pattern extraction, and attribute inference. While our attacks give an empirical lower bound on the privacy leakage, we also provide a theoretical upper bound on the privacy leakage metrics. Our experiments across various real-world data sets show that the membership inference attacks can infer a subset of candidate training records with high attack precision, even in challenging cases where the adversary’s candidate set is mostly non-training records. In our pattern extraction experiments, we show that an adversary is able to recover email ids, passwords and login credentials from large transformer-based language models. Our attribute inference adversary is able to use underlying training distribution information inferred from the model to confidently identify candidate records with sensitive attribute values. We further evaluate the privacy risk implication to individuals contributing their data for model training. Our findings suggest that different subsets of individuals are vulnerable to different membership inference attacks, and that some individuals are repeatedly identified across multiple runs of an attack. For attribute inference, we find that a subset of candidate records with a sensitive attribute value are correctly predicted by our white-box attribute inference attacks but would be misclassified by an imputation attack that does not have access to the target model. We explore different defense strategies to mitigate the inference risks, including approaches that avoid model overfitting such as early stopping and differential privacy, and approaches that remove sensitive data from the training. We find that differential privacy mechanisms can thwart membership inference and pattern extraction attacks, but even differential privacy fails to mitigate the attribute inference risks since the attribute inference attack relies on the distribution information leaked by the model whereas differential privacy provides no protection against leakage of distribution statistics.
The dissertation on this project can be found here: https://libraetd.lib.virginia.edu/public_view/1r66j2137. This project was funded by the NSF grants #1717950, #1804603, and #1915813. We would also like to thank Lockheed Martin Corporation for their funding and support.